演算コアによる演算精度の向上
富士通研究所は2017年4月24日、ディープラーニングの学習処理に用いるデーターのビット幅を削減することで、ニューラルネットワーク構造や学習方式を変えずに学習用ハードウェアの電力効率を向上させる回路技術を開発したと発表した。これにより、クラウド上のサーバーやエッジサーバーなど様々な場所で、大規模なディープラーニング処理による高度なAI技術の適用領域を拡大できるという。
一般的にディープラーニングの学習用ハードウェアでは32ビットの浮動小数点と呼ばれるデーター形式で演算処理を行う。これを16ビットやそれ以下にビット幅を削減したり、整数で演算を行うハードウェアを用いたりすれば、演算量を削減し電力効率を高めることができる。しかし一方で、演算の途中で演算に必要な精度が不足して学習ができなくなる、ディープラーニングの認識性能が劣化するなどの課題もあった。
今回開発されたのは、学習過程での演算器のビット幅や、学習結果を記録するメモリーのビット幅を削減して電力効率を向上させる回路技術だ。この技術は、整数演算を基にディープラーニングの学習プロセスに特化してビット幅を削減した独自の数値表現と、多層ニューラルネットワークの層ごとに演算中のデーターを随時解析しながら、演算精度を保つように小数点の位置を自動的に制御する演算アルゴリズムを用いる。
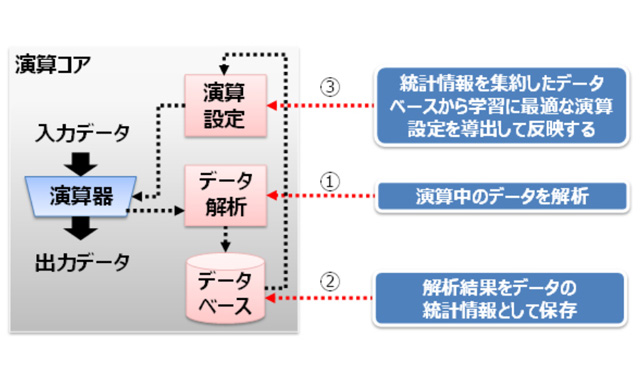
この技術を用いたディープラーニングの学習用ハードウェアの演算コアには、演算中のデーターを解析するブロック、解析したデーターの分布を保存するデーターベース、および演算の設定を保持するブロックがある。データー解析ブロックで学習中に演算器の出力データーを解析し、データー分布を表す統計情報としてデーターベースに保存。その分布から、学習精度向上のために十分な演算精度を保てるよう最適な設定をして演算を進める。この回路技術により、浮動小数点で行われていた演算を整数で行うとともに、32ビットを8ビットに削減することで消費電力の削減が可能になる。
同技術を実装したディープラーニング学習用ハードウェアを想定したシミュレーションにおいて、手書き数字認識によく使われる畳み込みニューラルネットワークのLeNetを用いた例では、32ビットの演算器で行った場合と比べ、演算器やメモリーの消費電力を約75%削減できることが確認された。一方、32ビット浮動小数点演算での学習結果が98.90%の認識率であったのに対し、16ビットで98.89%、8ビットでも98.31%の認識率で学習できたという。
近年、IoTとそれに伴うディープラーニングなどの機械学習の進展により、学習データは増大し、ディープラーニングのニューラルネットワークは大規模化が進んでいる。通信量やストレージ量の削減のため、クラウドだけではなくデーターが生成される場所に近いエッジ側で学習を行いたいというニーズも高まっている。今回の技術による電力削減で、大量のデーターが必要なディープラーニング学習処理をクラウド上のサーバーからエッジサーバーに適用していくことも可能になる。
同研究所では、この技術を富士通のAI技術「Human Centric AI Zinrai(ジンライ)」の1つとして、2018年度の実用化を目指す。