- 2023-12-5
- 制御・IT系, 技術ニュース, 海外ニュース
- ストリーミング, スマートフォン, セマンティック・ヒアリングシステム, ディープラーニング・アルゴリズム, ノイズキャンセリングヘッドホン, ヘッドホン, ワシントン大学, 学術, 音声コマンド
Paul G. Allen School/YouTube
ワシントン大学の研究者が率いるチームは、ユーザーがリアルタイムでヘッドホンから聞こえる音を選べるようにする、ディープラーニング・アルゴリズムを開発した。この技術により、装着者が聴きたい音を選べるようになる。
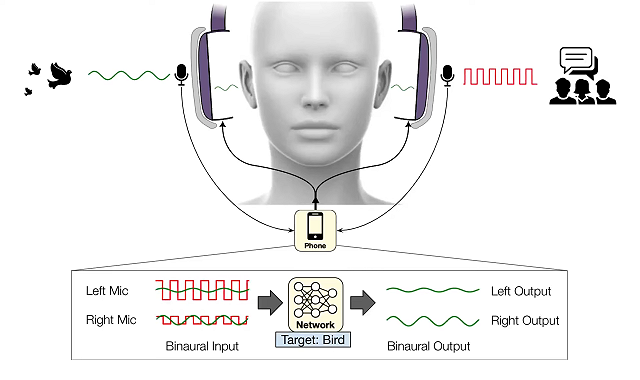
従来のノイズキャンセリングヘッドホンは、聞いている音声以外の環境雑音を打ち消すことはできるが、どの音をキャンセルするかは選べない。室内で仕事をしている人は、自動車のクラクションの音を聞きたくないだろうが、交通量の多い道路を歩いている人はそうとは限らない。そこでワシントン大学の研究者が率いるチームは、ユーザーがリアルタイムでヘッドホンから聞こえる音を選べるようにする、ディープラーニング・アルゴリズムを開発した。研究チームはこのシステムを 「セマンティック・ヒアリングシステム」と呼んでいる。
ヘッドホンはキャプチャしたオーディオを、接続されたスマートフォンにストリーミングし、スマートフォンはすべての環境音をキャンセルする。ヘッドホンを装着している人は、音声コマンドかスマートフォンのアプリを使って、サイレン、赤ちゃんの泣き声、話し声、掃除機、鳥のさえずりなど20種類の音の中から、どの音を取り入れるかを選択でき、選択された音だけがヘッドホンから再生される。
セマンティック・ヒアリングを実用化する上で一番重要なのはその処理速度だ。ヘッドホンを装着している人が聞く音は、視覚と同期している必要がある。誰かに話しかけられてから2秒後にその人の声が聞こえてくるのではなく、100分の1秒以内に音を処理する必要がある。この時間的制約のため、セマンティック・ヒアリングシステムは、堅牢なクラウドサーバーではなく、スマートフォンなどのデバイス上で音を処理しなければならない。さらに、異なる方向からの音が異なる時間に人の耳に届くため、システムはこれらの遅延やその他の空間的手がかりを保持しなければならない。
オフィス、道路、公園などの環境でテストしたところ、システムは、サイレン、鳥のさえずり、アラーム、その他のターゲット音を抽出することができた。22人の参加者が、対象音に対するシステムの音声出力を評価したところ、平均して元の録音に比べて品質が向上したと回答した。
しかしこのシステムでは、歌と人間の話し声のように特性がよく似ている音を区別するのが困難なケースもあった。研究者たちは、より多くの実世界のデータでモデルを訓練することで、これらの結果が改善される可能性があると指摘している。
関連情報
New AI noise-canceling headphone technology lets wearers pick which sounds they hear | UW News