NECは2019年8月19日、従来の約半分の量の学習データでも、高精度の識別能力を発揮できるディープラーニング技術を開発したと発表した。
ディープラーニングにおいて識別精度の向上には、識別が難しい対象や状況の学習データを多く学習させることが有効だ。ものづくりの分野において、外観検査をディープラーニングで行うには不良品データの学習が必要だが、発生頻度の低い不良品は大量に得ることが難しい。このため、不良品データの収集や模擬データ作成に多くの時間とコストが必要だった。
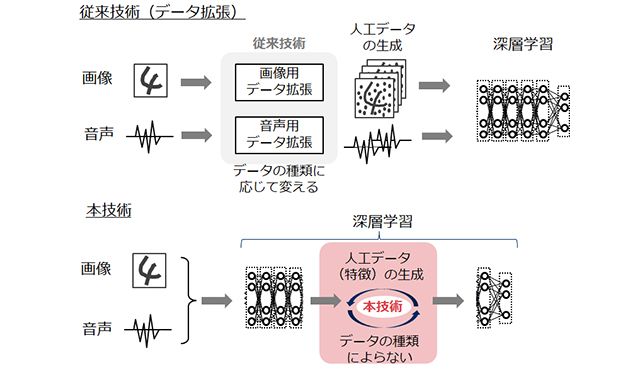
これらの問題に対して、従来は学習データを加工/変形させることでデータ量を増やす「データ拡張」という方法が用いられていた。しかし、具体的に識別精度を高めるまでのレベルには到達しておらず、データ加工にも専門的な知識が必要だった。
今回開発した技術は、人間の脳の仕組みを模したモデリング手法であるニューラルネットワークの中間層で得られる特徴量を意図的に変化させる。これにより、識別が難しい特に苦手な領域の学習データを集中的に人工生成し、識別精度を高めるものだ。手書き数字認識や物体認識で評価したところ、従来の約半数の学習データ量でも認識精度が変わらないことが確認できた。
また、従来のデータ拡張では、画像や音声などのデータの種類によってデータの生成方法を変える必要があったが、今回開発した技術では自動的に学習データを生成できるため、さまざまな種類のデータに対して、専門的な知識や調整が不要になる。