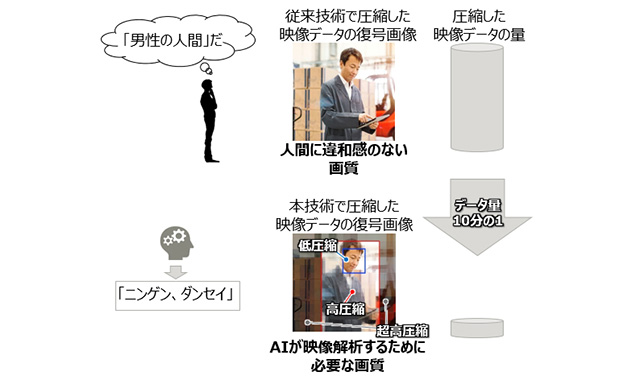
富士通研究所は2020年3月5日、AI(人工知能)が認識できる必要最小限のサイズまで高精細、大容量な映像データを高圧縮する技術を開発したと発表した。これまでの人間による視認を目的とした圧縮技術に比べ、映像データを10分の1に圧縮できる。
富士通研究所がこの技術を開発したのは、映像を圧縮すると圧縮率に応じて画質が劣化するため、AIが注目している領域を過度に圧縮すると認識率が低下するからだ。本技術は、映像データ1コマ1コマの画像において、AIが判断材料として認識している対象物の領域を自動的に解析し、領域ごとにAIが認識できる必要最低限な画質で圧縮することで、認識率の低下を防ぐ。
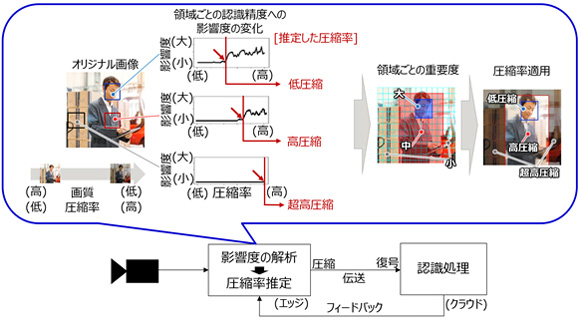
AIの認識精度を元に圧縮率を推定
具体的には、まず、圧縮特有の画質劣化が与える認識精度への影響を、画像の領域ごとに解析し、AIの認識結果も踏まえて、認識精度に影響しない圧縮率を自動推定する。
次に、画像全体の圧縮率を変えて画質を変化させ、その圧縮率を変化させた時の認識結果への影響度を格子状に区切った画像領域ごとに集計することで、AIが認識する過程における特徴の重要度合いを全ての領域ごとに判定する。
最後に、その各々の領域において認識精度を急激に劣化させる直前の圧縮率を認識精度に影響しない圧縮率として推定する。そして、連続する画像におけるAIの認識結果をフィードバックして必要最小限まで圧縮率を高める。
工場で梱包作業中の複数作業員の様子を4Kの高精細カメラで撮影した映像に開発技術を適用したところ、認識精度の劣化なくデータサイズを10分の1に削減できることが確認された。開発技術は、クラウド上に蓄積された複数の映像データのほか、映像以外のセンサーデータや売り上げなどの実績データなどを組み合わせた高度な映像データなど、さまざまな映像データの解析への活用が期待できる。