- 2022-1-9
- 制御・IT系, 技術ニュース, 海外ニュース
- AI, DeepSpeed, GPT-3, Megatron, Megatron-LM, Megatron-Turing Natural Language Generation(MT-NLG), Microsoft, Microsoft Research Blog, NVIDIA, 自然言語処理(NLP)
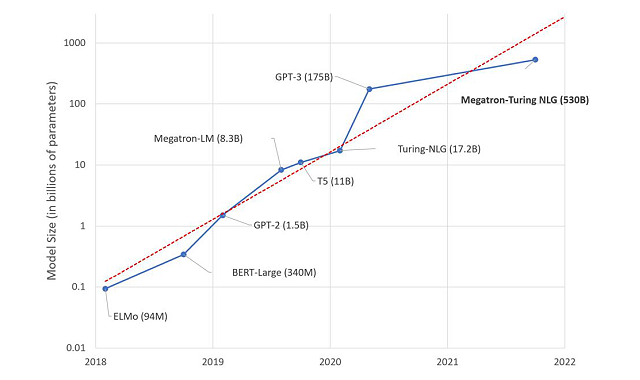
米Microsoftは2021年10月11日のMicrosoft Research Blogの記事にて、新たな自然言語生成モデル「Megatron-Turing Natural Language Generation(MT-NLG)」を紹介した。MicrosoftのDeepSpeedとNVIDIAのMegatronを利用した同モデルのパラメーター数は、既存の最多パラメーター数を持つ言語モデル「GPT-3」の約3倍となる約5300億個にもなり、補完や予測、読解、常識推論、自然言語推論、語義の曖昧性解消といったタスクの精度を飛躍的に高めるという。
自然言語処理(NLP)のTransformerベースの言語モデルは、大規模なデータセットと計算、高度なアルゴリズムやソフトウェアのおかげで近年急速な進歩を遂げている。言語モデルは要約、自動ダイアログ生成、翻訳、セマンティック検索、コードの自動補完といった用途に活用され、パラメーターやデータ、トレーニング時間が増すほど、言語をより豊かに、ニュアンスまで含めて理解できるようになっていく。
MicrosoftとNVIDIA はDeepSpeedとMegatron-LMの資産を生かし、効率的でスケーラブルな3D並列システムを構築。テンソルのスライス処理やパイプラインの並列処理を組み合わせることで、効率性を最大限に高めて運用できるようにした。
Microsoft Research Blogには、「DeepSpeedとMegatron-LMによる技術革新は現在と未来のAIモデル開発にとって有益なものになり、大規模なAIモデルをより安価で迅速にトレーニングできるようにするだろう」と記されている。