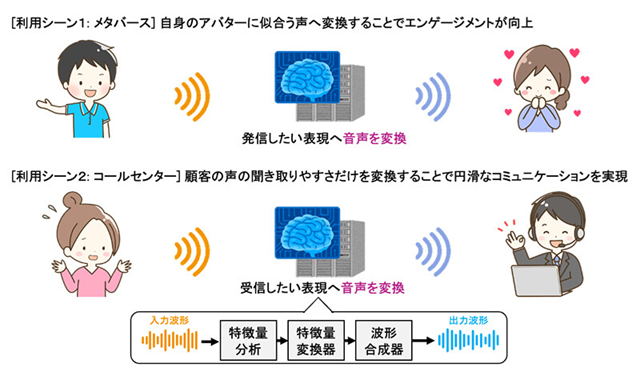
日本電信電話(NTT)は2024年6月17日、特定の話者の声を他の話者が話しているように、低遅延かつ高品質に音声変換する技術を開発したと発表した。
今回開発したのは、深層学習(ディープラーニング)に基づくリアルタイム音声変換技術で、ある話者の音声特徴量を別の話者の音声特徴量に変換する。エンコーダーとデコーダーの2つモジュールで構成されており、エンコーダーが入力音声から中間特徴量を抽出し、デコーダーが中間特徴量に目標とする話者の情報を付与することで、変換後の音声の特徴量を生成する。
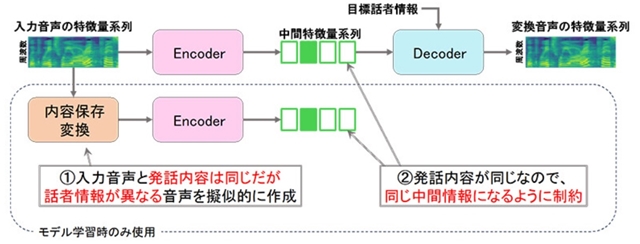
特徴量の変換方法
通常このような方法では中間特徴量に入力話者の情報が多く残留してしまう。しかし今回は、入力音声と同じ発話内容で話者情報が異なる音声を疑似的に生成し、疑似音声の中間特徴量に近づけるようにしたことで、入力話者の話者情報の残留を1万分の1にした。これにより元の話者への依存性が低い高品質な音声変換が可能になった。
また、一般的な音声変換で処理遅延の要因となっている未来フレームを用いず、当該時刻と過去の音声フレームのみを用いることで遅延を低減。音声変換システムにありがちなフィードバック音声遅延による発話のしづらさの発生を抑えた。
今回開発した技術は、オンライン会議での声質の改善や発声機能障がいへの活用、よりネイティブに近い英語の発音、説得力のあるスピーチや緊張による声の震えの解消など、さまざまなシーンでの活用が期待される。