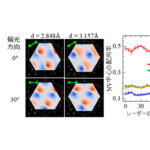
機械学習での処理の流れと今回提案した計算方式の適用例
産業技術総合研究所は2018年5月29日、東京大学と共同で、機械学習での訓練処理の時間を短縮する計算方式と回路を考案したと発表した。高速化が難しい訓練処理の処理能力を最大で5倍に向上できることをシミュレーションで確認したという。
人工知能技術の1つである機械学習は、入力をモデルにより処理し識別結果や将来の予測などを出力する推論処理と、大量のデータを学習してより良いモデルを構築する訓練処理からなる。推論処理の高速化手法は多いが、訓練処理の高速化手法は決定的なものがなく、長時間の処理が必要だった。
訓練処理では通常32ビットか16ビットの数値表現が用いられる。一般には、数値を表すビット数を大きくすると計算精度が向上する一方で、処理を行う回路の規模が大きくなって処理時間や消費電力が増える。逆にビット数を小さくすると、回路規模が小さくなり処理時間や消費電力は減少するものの計算精度が悪くなる。
今回の研究では、訓練処理で現れる数値の範囲を解析。限られたビット数で全てのデータを精度よく表現できるデータ形式と、小さいビット数でも乗算と加算が正確に行える計算方式を考案した。IEEE標準の32ビットデータ形式は符号1ビット、指数部8ビット、仮数部23ビットで構成されるのに対して、開発した9ビットデータ形式は符号1ビット、指数部5ビット、仮数部3ビットで構成。32ビット形式の場合、演算回路の約80%を乗算回路が占めるが、9ビットデータ形式では仮数部が3ビットに減ったため、乗算回路は32ビット形式と比べて1/30程度となる。また、指数部のビット数や演算回路への入力を減らしたことで、データをメモリーなどから演算回路まで移動させるのに必要なエネルギーも約1/4まで削減できる。
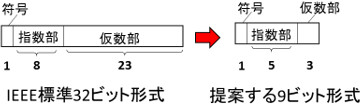
一方で、生成したモデルを用いた推論の精度に大きく影響する加算回路は仮数部を23ビットに保った。23ビットにすることで、絶対値が大きく異なる2つの数を加減算するときに起こる情報落ちを防ぎ、訓練処理の精度が向上する。加算回路で仮数部を23ビットに増やしても回路全体の大きさへの影響は少ない。
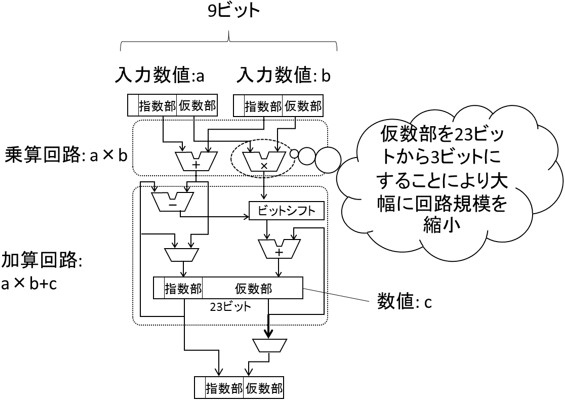
今回開発した計算方式をもつ演算回路
今回考案した回路では、まず2つの入力を9ビット形式で受けつけ乗算する。次に、乗算結果の仮数部を23ビットに変換。ビットシフト処理によって桁あわせした後、23ビットで加算を行う。そして、加算結果を再び9ビット形式に変換して出力する。
研究グループは、この計算方式と回路を模したシミュレーションによって推論の精度や消費電力を推定。その結果、32ビット形式を用いた場合と比べ、9ビット形式を用いて生成したモデルによる推論の精度の劣化は2%程度に抑えられることが分かった。一方、回路規模や消費電力は1/5程度に縮小できると推定された。これは、同一規模のハードウエアを用いた場合には5倍程度の高速化が可能であることを意味する。
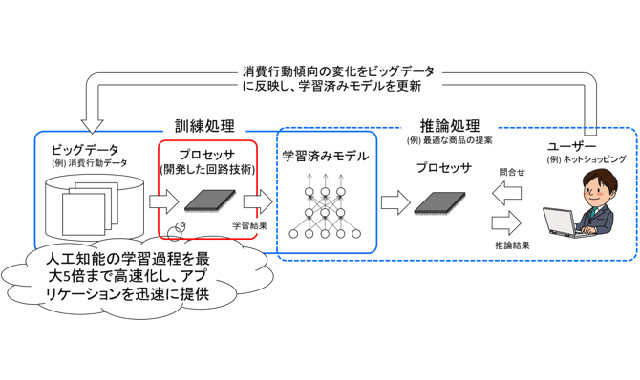
今回考案した回路が実装されたプロセッサを用いれば、機械学習を用いたサービスを最適化する場合などに、訓練処理を大幅に短縮できると考えられている。利用例として、ネットショッピングの履歴を参考に最良の商品を提案する推論処理があげられる。消費行動の傾向が変わりモデルを最適化するときは、ビッグデータに基づいて訓練処理を行ってモデルを改良する。モデル改良の時間が短くなればサービス事業者は新たなビジネスチャンスを獲得でき、利用者の利便性も向上する。
今後は、更に多くの問題で提案した方式の有効性を検証するとともに、ハードウェアを試作して実現可能性を検証し、実用化を進めるという。