NTTは2019年5月27日、人の話し声以外の音を自動的に文字で表現する技術を開発したと発表した。
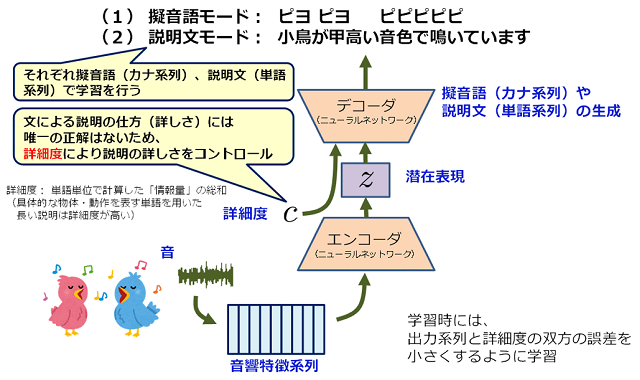
近年、音声認識技術の進展によって、人の話し声を高い精度で自動的に文字化することができるようになってきた。しかし、話し声以外の音を文字化することには限界があった。今回の研究では、多層ニューラルネットワークに、音の特徴の時系列と、擬音用の文字列や説明文用の単語列との対応を学習させることで、音から文字列への変換を可能にした。音響信号に対してどのような擬音語や説明文が適切なのかを、教師データによって多層ニューラルネットワークに学ばせる。
このニューラルネットワークは、音響信号特徴の時系列を「潜在特徴」という固定次元ベクトルに変換する「エンコーダ」と、その潜在特徴をテキストに変換する「デコーダ」から構成されている。学習段階ではその双方を学習させる。生成段階では、学習済みエンコーダに音響信号特徴の時系列を入力して潜在特徴を取得。それを学習済みデコーダに入力することで、対応する文字列を得る。
どの程度適切な擬音語生成ができるのかの評価を実施したところ、客観的実験では単語誤り率7.2%、平均音素誤り率2.8%と、ほぼ妥当と考えられる擬音語の生成ができることが分かった。また、生成された擬音語の主観的な受容度を実験によって調べると78.4%の受容率となり、人間による擬音語表現よりも上回る数値となった。
今回開発した技術では、場面や用途に応じて説明の詳しさのレベルを調整することができる。また、事前にタグ付けなどを施さなくても、音響データベースからテキストによる高精度の検索が可能になるという。
今回開発した技術により、単純な音響の検索だけではなく、動画中の音の文字化による視聴層の拡大や、人に近い音の感覚をAIに学ばせることによるAIと人とのコミュニケーションの円滑化などが期待できるという。