- 2022-12-9
- 制御・IT系, 技術ニュース
- AIアクセラレーター, AIチップ, DRP, DRP-AI, NEDO, エンドポイント学習システム, ルネサス エレクトロニクス, 人工知能チップ, 新エネルギー・産業技術総合開発機構, 研究

ルネサス エレクトロニクスは2022年12月8日、NEDO(新エネルギー・産業技術総合開発機構)が進める「高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発」で、複雑なタスクを処理する動的再構成プロセッサー(DRP)を用いた人工知能(AI)チップを開発したと発表した。電力効率が1W当たり10TOPS(10兆回/秒)と、従来技術と比べて最大10倍となっている。
少子高齢化に伴って労働人口が減少する中、社会で稼働するサービスロボットやセキュリティカメラに組み込め、かつ高度な人工知能(AI)処理ができ、リアルタイムで応答するAI機器が求められている。しかし、AI処理は大量の演算が必要で、既存のAIチップでは発熱が実用化の障害となっていた。
そこでルネサスは、DRPを用いて高いAI処理性能と低消費電力を兼ね備えた独自のAIアクセラレーター「DRP-AI」と、電力効率をさらに高めるAI軽量化技術を組み合わせたAIチップを開発。電力効率が従来技術と比べ最大10倍となる1W当たり10TOPS(10兆回/秒)となっている。また、DRPを活用した自律的に現場の環境やタスクの変化に対応するエンドポイント学習システムも開発し、その基本動作を実証した。
ルネサス独自のDRPをベースとしたAIチップは、チップ内の演算器の回路接続構成を処理内容に応じて動作クロックごとにダイナミックに切り替えながら、アプリケーションを実行できる。必要な演算回路だけが動作するため、低消費電力化と高速化ができる。今回、このDRPと積和演算ユニット(AI-MAC)を一体化したDRP-AIをベースに、軽量化したAIモデルを効率的に処理できる次世代AIアクセラレーターを開発した。
AI処理の高速化には、代表的なAIモデル軽量化手法のうち、認識精度に影響の少ない演算を省略する「枝刈り」を用いた。AIモデル内で認識精度に影響のない演算は、不規則に存在することが一般的なため、ハードウエア処理の並列性と枝刈りの不規則性とに差があり、大きな課題として効率的な処理ができないことが挙げられる。
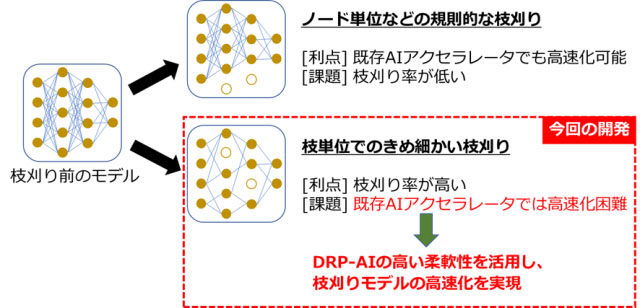
「DRP-AI」による枝刈りAIモデルの高速化
今回開発したAIアクセラレーターは、DRP-AIが持つ動的な回路切り替え技術などの高い柔軟性を活用。枝単位できめ細かく枝刈りした場合でも、演算を効率よくスキップできるため、認識精度に必要な演算のみに絞りつつ、高いハードウエア並列性を維持して処理できる。
演算量を最大90%削減する枝刈り率のAIモデルでは、従来技術に比べ最大で10倍高速化。1W当たり最大で10TOPSの電力効率を達成した。モデルにもよるが、演算量を枝刈りで90%削減した場合の認識精度は3%程度の低下にとどまり、ほぼ同等の精度が得られることがわかった。さらに、枝刈りモデルの最適化からハードウエア実装までエンドツーエンドで自動化するAI実装ツールを開発。多様なAIモデルをユーザーが容易に実装できる。
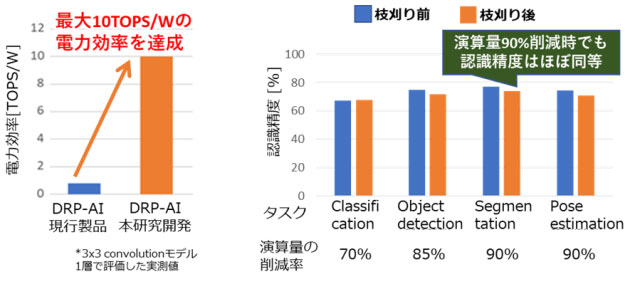
左)電力効率の比較、右)枝刈りによる演算量削減率と認識精度との関係
また、環境に自律的な対応ができるエンドポイント学習技術を開発。DRPが学習アルゴリズムの実装までできる高い柔軟性を有することを利用し、AIの実行と追加学習を同時並行してDRP-AI内で実行する。
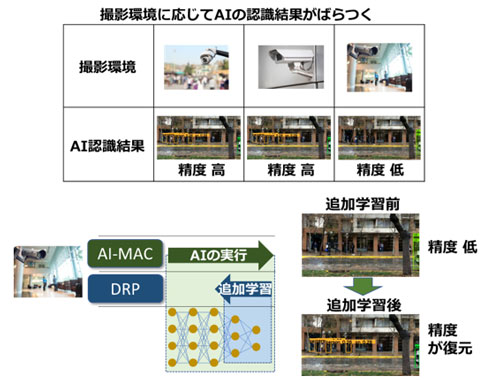
エンドポイント学習システムの概要
これにより、現場の動作環境やタスクの変化に自律的に適応していくエッジでの学習システムを構築できる。AIの実行を止めずにバックグラウンドで学習でき、追加学習のための時間の確保やデータ収集の手間が不要となるため、容易に運用できる。機器の設置場所やセンサーのばらつきによらず、リアルタイムで応答する高精度な組み込みAIの実行に対応する。
この技術を搭載したAIチップを試作し、10分の1に軽量化された畳み込み層の性能評価では、製品化されているエンドポイント機器向けAIプロセッサーとしては世界トップレベルの実効効率(1W当たり10TOPS)を実証。ルネサスの現行製品と比べても、10倍以上の電力効率となっている。
今後は、開発した技術に関する詳細評価と実証実験を進める。また、IoTインフラ事業向け製品への適用を計画している。