- 2024-5-2
- 制御・IT系, 技術ニュース, 海外ニュース
- AI, AIエージェント, GPT-4V, Meta, OpenEQA(Open-Vocabulary Embodied Question Answering), VLM(vision+language model), エピソード記憶EQA, オープンボキャブラリー, スマートグラス, ワールドモデル, 家庭用ロボット, 感覚モダリティ(sensory modalities), 能動的EQA, 評価フレームワーク
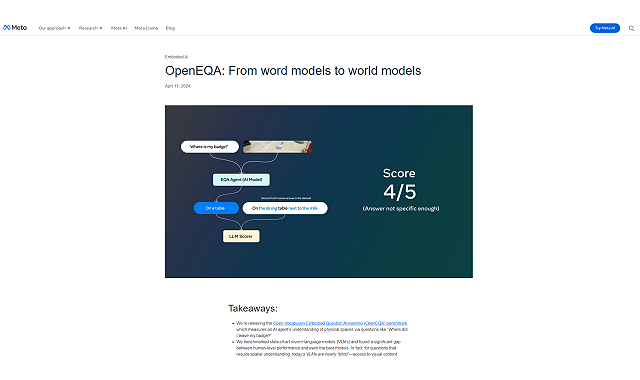
米Metaは、2024年4月11日、事前に定義されていない「オープンボキャブラリー」の質問を通じて、物理的空間を理解するAIエージェントの評価フレームワーク、「Open-Vocabulary Embodied Question Answering(OpenEQA)」を発表した。
家庭用ロボットやスマートグラスに搭載されるAIエージェントでは、周囲の状況を理解して人々を支援するための能力、「感覚モダリティ(sensory modalities)」が重要だ。この能力は、AIエージェントが言語を介して実世界を理解するもので、AIの内部に「ワールドモデル」と呼ばれる情報セットを構築する必要がある。
OpenEQAは、現実のユースケースに沿った1600種類以上の質問と回答のペア、180本以上のビデオを用いる。また、部屋などの物理的な環境を使い、AIエージェントを評価する。これは、人間が互いの概念理解を確認するのと同様に、AIエージェントの概念理解を確認するものだ。
OpenEQAには、2つのタスクがある。1つ目の「エピソード記憶EQA」は、AIエージェントが経験の記憶に基づいて質問に答えるタスク。2つ目の「能動的EQA」は、質問に回答するために必要な情報を入手すべく、環境内で行動を起こすためのタスクだ。
同社がOpenEQAを使用して、最新のvision+language model(VLM)のベンチマークを測定したところ、最も高性能なモデルとされるGPT-4Vの48.5%でさえ、人間の能力(85.9%)と大きな隔たりがあった。同社は、空間的な理解を測る質問では、最も優れたVLMでもほぼ無力と結論付けている。
同社はコメントとして、OpenEQAの活用によって我々が見る世界をAIに理解させ、コミュニケーション能力の研究が進展することを願っている、との趣旨を述べた。