- 2023-5-5
- 制御・IT系, 技術ニュース, 海外ニュース
- Meta, Segment Anything 1-Billion mask dataset(SA-1B), Segment Anything Model (SAM), コンピュータビジョン, セグメンテーション, セグメンテーションデータセット, ゼロショット転送, パーミッシブオープンライセンス(Apache 2.0), 画像セグメンテーションモデル
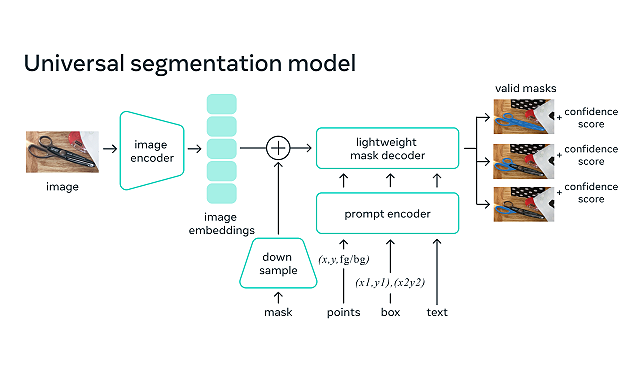
米Metaは2023年4月5日、画像や映像内のオブジェクトを識別する、画像セグメンテーションモデル「Segment Anything Model (SAM) 」と、過去最大のセグメンテーションデータセットである「Segment Anything 1-Billion mask dataset(SA-1B)」を公開した。
セグメンテーションとは、画像のどのピクセルが該当するオブジェクトに属するかを特定することだ。コンピュータが画像や動画などから情報を引き出す技術である、コンピュータビジョンの中核的なタスクであり、科学的画像の分析から写真の編集まで、幅広いアプリケーションで使用されている。
SAMは、オブジェクトが何であるかという一般的な概念を学習しており、トレーニング中に遭遇しなかったオブジェクトや画像タイプも含め、あらゆる画像や動画内のあらゆるオブジェクトに対するマスクを生成することができるという。また、幅広いユースケースに対応できる汎用性を備えており、水中写真や細胞顕微鏡など、新しい画像の「分野」でも追加トレーニングを必要とせず、すぐに使用できる(ゼロショット転送)。
最終的なデータセットには、ライセンスされ、プライバシー保護された約1100万枚の画像から収集された、11億枚以上のセグメンテーションマスクが含まれている。これらのマスクは、人間による評価試験で高い品質と多様性を持つことが示された。
SAMは、パーミッシブオープンライセンス(Apache 2.0)のもとで利用可能で、ユーザーはデモ画像を見て、自身の画像でSAMを試すことができる。SA-1Bデータセットは研究用に利用可能だ。
関連情報
Introducing Segment Anything: Working toward the first foundation model for image segmentation