NTTと早稲田大学は2023年6月16日、ソフトウェアなどのプログラムの中に含まれる誤った正規表現の文字列抽出を検出し、自動的に修正する技術を世界で初めて開発したと発表した。この技術を使えば、専門知識が乏しくても、安全なサービスを作り出すことができるとしている。
正規表現は、ほとんどのプログラミング言語に組み込まれている技術で、ソフトウェアやWebサービスのユーザーIDの抽出などに幅広く利用されている。しかし、正規表現を用いたプログラムの動作を正確に理解することは難しく、一般公開されているオープンソースのプログラムにも誤った正規表現が修正されないまま残っている例は少なくない。誤った正規表現はシステムの誤動作を引き起こし、情報漏洩やサービス停止の原因となることから、大きなリスク要因となっている。
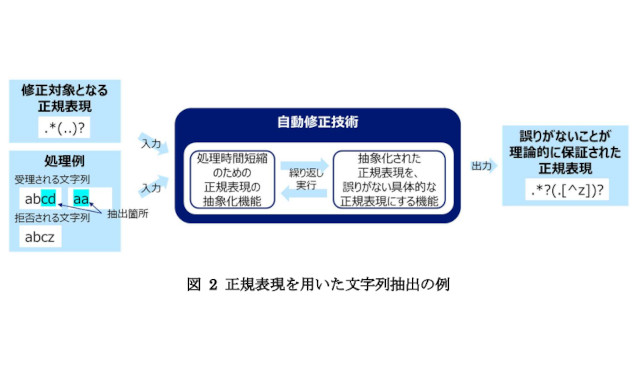
今回NTTは、正規表現の文字列抽出プログラムにおいて、プログラムの振る舞いを理論モデルとして厳密に定義。理論モデルに従って修正結果となる正規表現に誤りがないことを保証する条件を生成する方法を提案した。さらに条件を生成する方法を活用し、修正対象となる正規表現に加え、利用者が望む正規表現に対するポジティブな例(受理される文字列)とネガティブな例(拒否される文字列)を与えると、処理時間短縮のために正規表現を抽象化する機能と、抽象化された正規表現を誤りのない具体的な正規表現にする機能を交互に繰り返し実行して、理論的に正しさが保証された正規表現を出力するアルゴリズムを考案した。早稲田大はNTTが考案した手法の理論的な正確さを検証した。
NTTは、今回の技術を活用することで高度な専門知識や経験を持たない開発者でも安全なソフトウェアを作り出すことが可能になるほか、AIで作成したプログラムのチェックへの活用も期待できるとしている。
この技術は同年6月17日から22日まで、米フロリダ州で開催されるプログラミング言語分野の国際会議PLDI2023で発表される予定だ。