- 2024-9-2
- 制御・IT系, 技術ニュース
- GENIAC, LLM, NEDO, Tanuki-8×8B, 大規模言語モデル, 新エネルギー・産業技術総合開発機構, 東京大学, 松尾研, 生成AI, 研究, 経済産業省
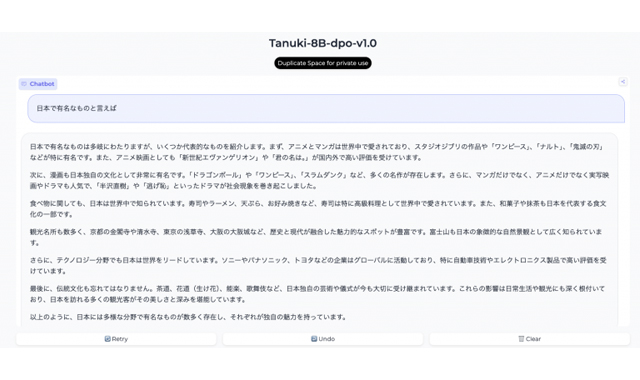
東京大学は2024年8月30日、経済産業省と新エネルギー・産業技術総合開発機構(NEDO)が推進する生成AIの開発プロジェクト「GENIAC(Generative AI Accelerator Challenge)」で、同大学工学系研究科技術経営戦略学専攻の松尾・岩澤研究室が大規模言語モデル「Tanuki-8×8B」を開発し、公開したと発表した。同モデル軽量版の「Tanuki-8B」をチャット形式で利用できるデモを期間限定で公開している。
GENIACは、日本の生成AIの開発力を強化するためのプロジェクトだ。同研究室は事業の採択を受けて、⺠間企業の社員や研究者、学⽣らでつくるチームを結成し、ゼロからのモデル開発に取り組んでいる。
開発工程は2つのフェーズに分かれており、フェーズ1では7チームに分かれてコンペティション形式で開発を進めた。フェーズ2ではフェーズ1の優勝チームが、さらに大規模なモデル開発に挑戦した。
「Tanuki-8×8B」はフェーズ1で優勝チームが構築した8Bモデルを8つに複製し、それぞれを専門家モデルとして分化/連携させることで動作するように効率的に追加学習された。特に作文、対話能力の向上に力を入れたといい、これらの能力を客観的に評価する指標「Japanese MT-Bench」を使った検証では、OpenAIの「GPT-3.5 Turbo」と同等以上の性能を達成した。
総合的な推論性能はGPT-4oなどの海外の最先端モデルに追いついていない部分がある。しかし、無機質で形式的な返答をする傾向にある海外モデルに比べ、共感性や思いやりのある返答や、自然な言葉遣いでの作文が得意だという特徴があった。
研究室は「今後、さらにモデル開発を継続していくことで、日本ならではのオリジナリティや競争力を兼ね備えた大規模言語モデル(LLM)群が誕生することが期待できる」としている。