- 2019-2-27
- ニュース, 制御・IT系, 技術ニュース, 電気・電子系
- AI, DNNアクセラレータ, SoC, ViscontiTM5, 先進運転支援システム, 東芝デバイス&ストレージ, 深層学習, 画像認識
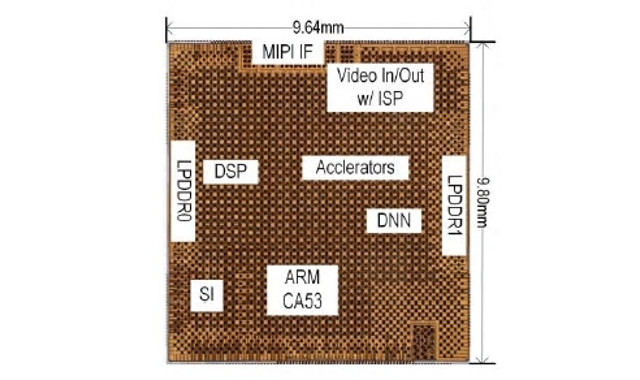
開発したSoC
東芝デバイス&ストレージは2019年2月26日、AI技術の1つである深層学習を用いた画像認識を、高速かつ低消費電力で実行する車載向けSoC(System on a Chip)を開発したと発表した。東芝の従来技術と比較して、処理速度は約10倍、電力効率は約4倍を達成したという。
近年、自動車市場では、自動ブレーキなどの運転支援システムの重要性が高まっている。運転支援システムの高度化には多様な交通標識や道路状況の瞬時の把握が必要だ。同システムの基幹となる画像認識SoCには、車載機器として実装可能な消費電力の水準を満たしながら、さらなる精度の向上と処理の高速化が求められている。
深層学習は人間の脳の神経回路をモデルとしたアルゴリズムで、従来のパターン認識や機械学習よりも高精度な認識が可能とされており、車載用途への活用が期待されている。一方、深層学習による画像認識では多数の積和演算の実行が必要で、通常のプロセッサで処理すると時間がかかり、高速で処理しようとすると多量の電力を消費してしまうというトレードオフの関係があった。
そこで同社は、深層学習による画像認識をハードウェア上で実行するDNNアクセラレータを開発。SoC上に実装することで、この課題を解決した。開発されたDNNアクセラレータは、3つの特長を持つ。
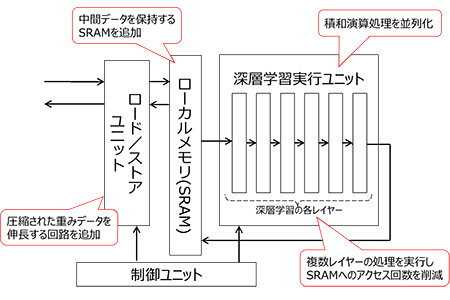
DNNアクセラレータの構造(一部)
第1の特長、積和演算プロセスの並列化では、256個の積和演算ユニットを搭載したプロセッサを4つ、DNNアクセラレータに設置。演算を並列に処理することで効率化し、画像認識の処理速度を高めた。
第2の特長は、SRAMへのアクセスにより消費される電力の低減だ。DRAMへのアクセスにより消費される電力の低減だ。従来のSoCでは、深層学習による画像認識を実行するユニットの近くに、演算プロセスの中間データを一時的に保持するためのメモリが配置されておらず、メモリへアクセスする度に多くの電力を消費する。加えて、処理に必要な重みデータを読み込む動作によっても電力消費が増加していた。
今回開発したSoCでは、中間データを保持する専用のSRAMを実行ユニットの近くに配置。そのSRAMに収まるように深層学習の推論処理を分割することで、DRAMへのアクセス回数を削減した。さらに、重みデータを事前に圧縮して保存しておき、読み込む際にそのデータを伸長する回路を追加することで、重みデータの読み込みに使用するデータ量も削減した。
第3の特長は、SRAMへのアクセスにより消費される電力の低減。今回開発したSoCでは各レイヤーをパイプライン接続し、中間データをSRAMへ書き込むことなく、1回のSRAM参照で複数レイヤーの処理を実行することで、消費電力を抑制。従来は、深層学習の推論処理の各レイヤーにおいて、それぞれの処理が終わるたびに SRAMを参照していたため、メモリ動作時に消費される電力が大きくなっていた。
今後は、SoCのさらなる精度向上や消費電力の抑制など開発を進め、車載向け画像認識AIプロセッサ「ViscontiTM5」として、2019年9月にサンプル出荷を開始する予定だという。